Project 3: Encrypt and Hash
IMPORTANT INFO - PLEASE READ
The projects are part of CS110P course project worth 2 credit points. As such they run in parallel to the actual course. So be aware that the due date for project and homework might be very close to each other! Start early and do not procrastinate.
Introduction to Project 3
In this project, we hope you can use all knowledge about computer architecture that your have learned in this course to optimize a program with encryption and hashing. We'll provide the program code, and your job is to modify the code to improve its time performance. The following will first introduce you to the basics of encryption and hash.
Encryption
Encryption is a reversible process that converts plaintext into ciphertext using an algorithm and a cryptographic key. It ensures data confidentiality, allowing authorized parties with the correct key to decrypt and recover the original data. Examples include AES (symmetric) and RSA (asymmetric) encryption.
In this project, our input is a string of plaintext, which we first encrypt to get a string of ciphertext. Here we use a stream cipher called ChaCha to encrypt this plaintext.
ChaCha is a modern stream cipher designed by Daniel J. Bernstein in 2008. It is an evolution of the earlier Salsa20 cipher, optimized for improved performance and security. ChaCha operates by generating a pseudorandom keystream from a 256-bit secret key, a 96-bit nonce (number used once), and a counter. This keystream is then combined with plaintext via XOR to produce ciphertext.
The ChaCha stream cipher generates a pseudorandom keystream through iterative transformations of an initial 512-bit state matrix. This matrix is initialized with a 256-bit key, 96-bit nonce, 32-bit block counter, and predefined constants (e.g., “expand 32-byte k”). The state undergoes 20 rounds of mixing via the quarter-round function, which performs sequential additions, XORs, and bitwise rotations on grouped state words. After processing all rounds, the final state is combined with the initial matrix and serialized into a 512-bit keystream block. Each block is produced by incrementing the counter, ensuring uniqueness.
Hash
Hash (or hashing) is a one-way function that transforms input data into a fixed-length string of characters (digest). It is irreversible and deterministic, meaning the same input always produces the same hash. Hashes verify data integrity (e.g., file checksums) or securely store passwords (e.g., using SHA-256 or bcrypt). Unlike encryption, hashing does not involve keys and cannot restore the original data from the digest.
Here we use a hash tree to transform the previously obtained ciphertext into a fixed-length sequence.
A hash tree (also known as a Merkle tree) is a hierarchical data structure used to efficiently verify the integrity of large datasets. It works by recursively hashing pairs of data blocks until a single root hash, called the Merkle root, is generated. Each leaf node represents the hash of a data block, while non-leaf nodes are hashes of their combined child nodes. This structure allows quick and secure verification of specific data elements without requiring the entire dataset to be rechecked. Hash trees are widely used in blockchain systems (e.g., Bitcoin, Ethereum), file-sharing protocols, and version control systems to ensure data consistency and tamper resistance.
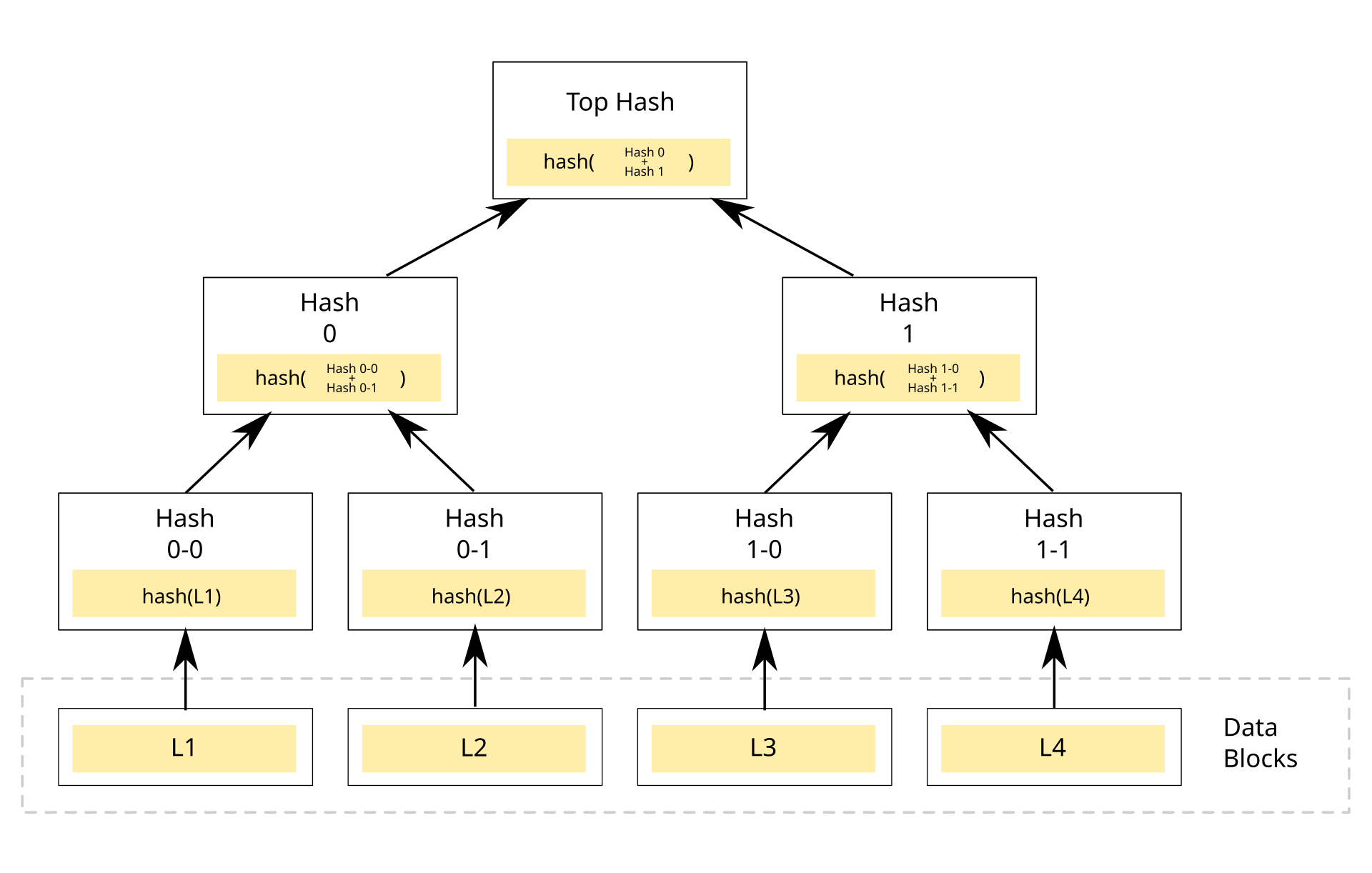
Here we only care about the root node of the Hash Tree and use it as the final output hash value.
Getting Started
Make sure you read through the entire specification before starting the project.
We provided the template in Github Classroom to get started.
Files
The framework contains the following files and folders:
- main.c: Contains the main function code.
- tool.c: Contains a tool for generating test data.
- src: Contains encrypt and hash function implementations. All the files you have modified should be in this folder including changes to the Makefile. Any changes outside this folder will be ignored.
- testcases: Contains some testcases. Before using it, you need to generate the corresponding test data with the provided tool.
- Makefile: Used to generate the program and tool. No modifications allowed. If you want to modify the compiler parameters, please modified the Makefile in src .
Test Locally
Due to the large size of the input files, we will not provide the test data directly, but we need you to generate the relevant data locally.
First use make all to compile the program and tool, and then use ./tool . /testcases/test_0.meta to generate the required data files, then you can use ./program ./testcases/test_0.meta to test your program.
Optimization Techniques
You can find many obvious optimizations in the implementation we provide, based on what you have learned in Computer Architecture. We are listing some of the possible approaches below:
Compiler
There are some optimization flags that can be turned on in GCC. The available flags for x86 ISA from GCC are listed here. However, we hope that you can do most of the optimization yourself, instead of relying on the compiler. So in this project, you are not allowed to use GCC's optimisation flags .
Multithreading
The loop of the algorithm is a good candidate for multithreading. You can use OpenMP or
pthread to parallelize.
SIMD instructions
SIMD processes multiple data in parallel. Part of this algorithm is also a good candidate for SIMD instructions. Some instruction about "srli", "slli", "or", "shuffle" may be helpful.
Loop unrolling
Loop unrolling can be used to reduce the overhead of the loop.
Cache Blocking
The main idea here is to make memory access more efficient and exploit memory locality.
Addition
Some students may want to try some SIMD instruction sets such as AVX512, but find that their computers do not support such instruction sets. In this case, you can choose to use Intel SDE to verify your correctness, or you can also use some commercial cloud environments. However, please note that autograder on gradescope does not support CPUID Flags like AVX512_BITALG, so if you want to use instruction with AVX512_BITALG CPUID Flags, you may need to implement additional logic in your code to determine if the environment supports this instruction.
Grading Policy
The total score for this project is 100:
- We will first run your code on small test cases on GradeScope (automatically). If your program does not produce the correct result, you will receive 0 points. As always, your code should not have any memory issues.
- After the deadline, we will test your code on our local machine and new test cases. Your grade on this part depends on the speedup of your code. If your code runs slower than adding the baseline (what we've provided), you will receive 0 points.
-
If your code runs at the same speed with bare
OpenMP, you will receive 50 points. - If your code ranks among the top 30 in performance in the class, you will receive 100 points.
-
For the rest, we will give a linear grade according to the speedup rate.
-
If your speedup is
3.0xand the bareOpenMPspeedup is5.0x, then your score will be(3.0 / 5.0) * 50 = 30.0points. -
If your speedup is
7.3xand the bareOpenMPspeedup is5.0x, while the 30th fastest code is10.0xthen your score will be50 + ((7.3 - 5.0) / (10.0 - 5.0)) * 50 = 73.0points.
-
If your speedup is
- If your code crashes during our test, you will receive 0 points.
- Your submission must contain meaningful use of multithreading technique and Intel SIMD intrinsics. Otherwise, you will get 0 points. This check will be done manually after the deadline so there will be no feedback on this from GradeScope.
Submission
Parameters for Speed Test
For the final test we will use 3 files with the same file size as the 3 tests provided and the total time will be used as the final time.
Server Configurations
GrapeScope Server (Used for correctness check):
The GrapeScope server is used for correctness check only because it has limited hardware resources and unstable performance. However, we have provided you with a Leaderboard for rough speed referencing.
-
Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single pti fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves ida arat pku ospke
- Memory: 3 GiB
Toast Lab Server (Used for final speed test):
-
Intel(R) Xeon(R) Gold 6348 CPU @ 2.60GHz 28 cores (56 threads) Details here
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local split_l ock_detect wbnoinvd dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req vnmi avx512vbmi umip pku ospke avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg tme avx512_vpopcntdq la57 rdpid fsrm md_clear pconfig flush_l1d arch_capabilities
- L1 i-cache 47 KiB (per core)
- L1 d-cache 32 KiB (per core)
- L2 cache 1.25 MiB (unified)
- L3 cache 42 MiB (unified)
- Memory: 120 GiB
More about the final speed test
The final test server in fact has two cpus that uses the NUMA architecture which is commonly used in modern servers. In the final test we will use numactl to run the program in a NUMA node. This is to avoid the impact of NUMA's memory arrangement on openmp. If you're interested, you can find out what numa is and why it has an effect on openmp. But we're not asking too much here, you can simply think of it as having only one CPU with 14 cores, as the same as the server configurations listed above.